来自objc的技术文章
一个像素是如何显示在屏幕上的
一个像素是如何显示在屏幕上的呢?让画面显示在屏幕上的方法有很多种,它们涉及到许多不同的框架和许多不同的函数和方法的组合.在这里我们来了解下屏幕背后的一些发生机制.我们希望这些能在你需要决定什么时候用什么方式来调试和修复性能问题的时候让你明白哪一个api是最合适你的. 我们主要是关注iOS,不过本文大部分讨论的东西也适用于OS X.
图形堆栈(Graphics Stack)
为了让像素点在屏幕上显示出来,渲染引擎做了许多事.一旦它们显示在屏幕的时候,每一个像素点都是由3种颜色构成:红,绿,蓝.在一个像素点上三个颜色单元用不同的强度来决定一个特别的颜色.在iPhone5的液晶显示屏上有1136 * 640 = 727040 个像素点,因此共有727040*3 个点彩色单元格.在15寸的macbookpro(retina) 这个数量大概是15.5百万(1550万)个彩色单元格,所有图像堆栈同时工作来保证每一个彩色单元格能用正确的强度点亮.当你全屏滚动的时候,所有的这些彩色单元格在1秒内都要更新60次,这是一项非常繁重的工作.
软件部分(The Software Components)
简单的来看,软件栈大概是长这样的
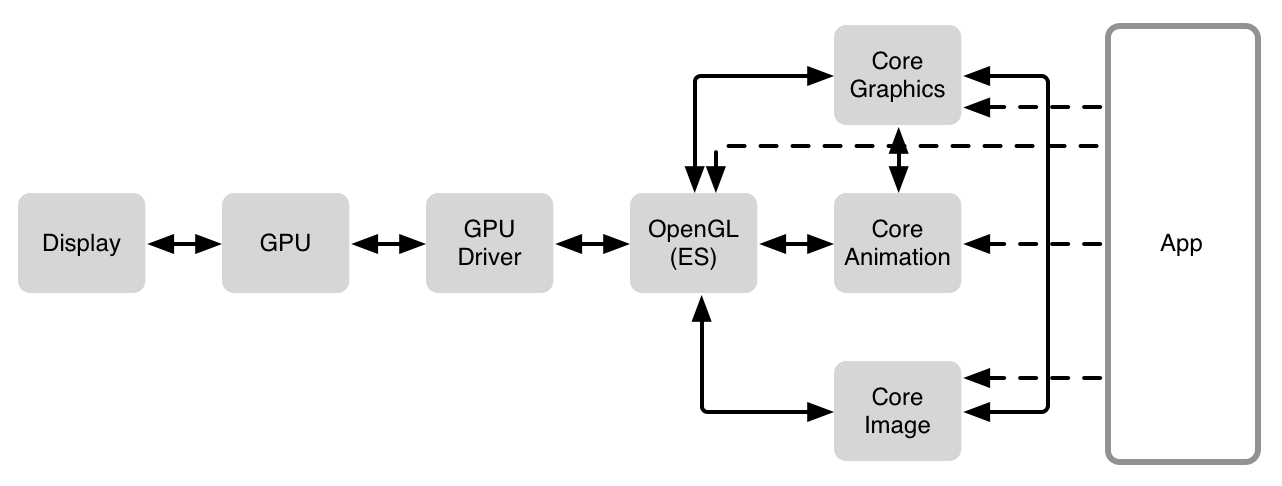
在display的上一层是GPU(graphics processing unit(图像处理单元)),GPU是一种高度并发的处理单元,是专门设计用来进行图像的平行计算的.有了它才是的像素的更新计算并实时显示到屏幕上成了可能并.同时行计算的能力也使得它在处理合并相反的纹理时候非常高效.对于这类工作相比于cpu速度快,并且能耗低.正常的cpu有非常广泛的用途.要处理非常多不同的事,因此在cpu上进行compositing会相对显得慢.
GPU驱动 是一小段代码 用来直接和GPU交互的,每种GPU都不大一样,因此driver使得他们可以用更统一的接口来面对下一层例如openGL/openGL ES.
OpenGL 是用来渲染2D和3D图像的API.尽管GPU是一种非常定制化的硬件,Open GL能和GPU紧密合作,进一步放大GPU的能力来加速图像的渲染.对很多人来说OpenGL似乎看上去很底层,但是,在1992年首次发布的时候,它是软件层面与GPU进行交互的第一种主要的标准化方法,这是一次重大的飞跃,由此以来,开发人员不用为每个GPU去重新写他们的软件.
在OpenGL之上就有一些不同了,在iOS中几乎每件事都需要通过core Animation,但是在 OSX中,经过Core Graphics绕过Core Animation的情况并不少见, 对于一些特殊的程序来说,特别是游戏,他们可能直接和OpenGL/OpenGl ES进行交互. 因此事情就变得更加的复杂了,因为Core Animation在一些渲染的情况下使用到了CoreGraphics. 例如AVFoundataion,Core Image,或者其他混合着访问.
有一点要铭记于心,GPU是一种非常强大的图形硬件,并且在显示像素的功能上扮演着至关重要的角色. 他连接着CPU. 在硬件上还有一系列的BUS(总线)在他们之间.同时也有例如OpenGL,Core Animation 和Core Graphics 等框架协调 GPU 和 CPU 之间的数据传送.为了让你的像素顺利显示在屏幕上,一些处理必须在CPU中进行.然后数据传送到GPU. GPU也将进行处理,最后像素显示在屏幕上.这过程中的每一个部分都有其挑战在里面,因此需要权衡考虑.
硬件扮演的角色 (The Hardware Players)
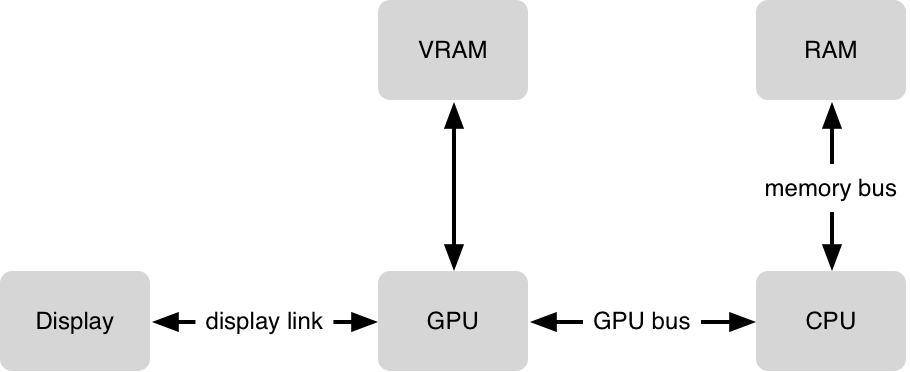
让我们来简单的看看其中所面临的挑战.GPU需要将一个位图进行1秒60次的复合计算.每一个位图需要占用VRAM,因此对于GPU能占用的位图数是有限制的.尽管GPU在compositing计算上超级高效,但是某些复合计算任务是非常复杂的,并且GPU在16.7ms内能做的事是有限的.
下一个挑战是将你的数据传送给GPU,为了让GPU拿到数据,必须将数据从ram传到vram.这个过程称为上传到cpu,这看上去无关紧要,但是如果位图占据很大的空间的时候,这就非常的消耗时间.
最后CPU运行程序,你必要告诉告诉CPU从你的bundle中加载一张png图片并且解压它.这些都在CPU进行,当你想要显示解压后的图片,数据需要被传递给GPU.对于CPU来说,像显示文本这样平凡的事情是一项极其复杂的任务,它需要Core Text和Core Graphics框架之间的紧密集成以从文本生成位图,一旦准备就绪.它将用textrue的形式传递给GPU.准备用来显示.当你滚动或者其他操作屏幕上的text.非常相同的texture将被重复使用.并且CPU将告诉GUP数据存储在哪一个新位置.因此GPU能够重新复用已经存在的texture.CPU不需要去重新渲染the text. Bitmap数据也不必要去重新上传.这些只是说明了其中的一些复杂性.
在这些概述后,我们将深入了解一些研究一些其中涉及的技术.
复合计算 (Compositing)
在图像的世界里复合计算描述的是把多个不同的位图放一起最终计算出你在屏幕上呈现的样子,听起来很容易,实际上是相当复杂性和需要相当大的计算量的.
让我们忽略一些复杂的案子并且假设任何东西在屏幕上都是一个texture,texture就是一个RGBA值的正方形,也就是说,对于每个像素,我们都有红色,绿色和蓝色以及一个alpha值.在核心动画世界中,这基本上就是CALayer.
让我们简化下步骤,每一个图层是一个texture,并且所有这些纹理都以某种方式彼此堆叠.对于屏幕上的每个像素,GPU需要确定如何混合/混合这些纹理以获得该像素的RGB值,这就是合成.
如果我们有在一个texture上盖上第二个texture,GUP将这个图层复合到第一个图层上.有许多种不同的混合模式,但是我们假设两个图层都是像素对齐,那么我们将使用常规的混合模式,每一个像素点的计算结果是下面公式得出来的
1
R = S + D * (1 - Sa)
来源颜色(上面texture)加上目标颜色(底层texture)乘以 1减去来源颜色的透明值,假设工式中的颜色都已经预计算了他们的透明值.
显然这里有很多事情要做.让我们先假设所有纹理都是完全不透明的,即alpha =1.如果目标(下部)纹理是蓝色(RGB = 0、0、1),而源(顶部)纹理是红(RGB = 1,0,0),并且因为Sa为1,所以结果是R = S结果就是来源的红色,正如我们预期的一样.
假如来源图层是50%的透明度,即 alpha = 0.5,因为alpha分量已预先乘以RGB值,则S的RGB值为(0.5,0,0) 该公式将如下所示:
1
2
3
0.5 0 0.5
R = S + D * (1 - Sa) = 0 + 0 * (1 - 0.5) = 0
0 1 0.5
我们最终得到的RGB值为(0.5,0,0.5),它是饱和的“李子”或紫色.当一个透明红色混合到蓝色的情况下这完全符合你直观的预期.我们刚才所做的是将一个纹理的一个像素合成另一个纹理的另一个像素.GPU需要对两个纹理重叠的所有像素执行此操作.如您所知,大多数应用程序具有多个图层,因此需要将纹理合成在一起.即使GPU是经过高度优化以执行此类操作的硬件,这也使GPU处于繁忙状态.
不透明和透明(Opaque vs. Transparent)
当来源texture是完全不透明的时候,结果图像是和来源texture一致的,这样GPU节省了很多工作,因为它能简单的拷贝来源颜色直接混合集合,但GPU并不会被告知所有的像素是否都是不透明的.只有程序员知道你把什么盖在图层上面.因此CALayer有一个 opaque属性.如果这是YES,那么GUP将不会做任何混合动作而是忽视任何这个图层之下的东西,直接拷贝图层.这样GPU省了一堆事.Instruments里有color blended layers 的功能.他可以让你看到哪一个图层被标记为透明.这样GPU将会做混合.做不透明图层的计算更省资源因为计算少.
因此如果你知道你的图层是不透明的,记得将opaque设置为YES,如果你加载一个图片没有alpha通道并且用UIImageView来显示,那么这个将会自动设置.但是请注意,没有Alpha通道的图片与Alpha为100%的图片之间存在很大差异.在后一种情况下,Core Animation必须假定可能存在Alpha不是100%的像素.在Finder中,您可以使用“获取信息”并检查“更多信息”部分.它会判断图像是否具有Alpha通道.
像素对齐和不对齐(Pixel Alignment and Misalignment)
到目前为止,我们已经研究了像素与显示器完全对齐的图层.当所有的东西都是像素对齐的,我们就得到了我们目前所看到的相对简单的数学.当GPU需要计算出屏幕上的像素应该是什么颜色时,它只需要查看屏幕像素上方的层中的一个像素并将这些像素合成在一起.或者,如果顶部纹理不透明,GPU可以简单地复制顶部纹理的像素.
当一个层的所有像素与屏幕的像素完全对齐时,它就是像素对齐的.原因主要有两个,第一个是缩放;当一个纹理被放大或缩小时,纹理的像素不会与屏幕的像素对齐.另一个原因是纹理的原点不在像素边界上.
在这两种情况下,GPU再次需要做额外的数学运算.它必须将源纹理中的多个像素混合在一起才能创建用于合成的值.当所有的东西都是像素对齐的,GPU的工作就更少了.
同样,核心动画仪器和模拟器有一个称为“颜色未对齐图像”的选项,当CALayer实例发生这种情况时,它会向您显示.
遮罩(Masks)
一个图层可以有一个遮罩,遮罩是Alpha值的位图,在将其合成到其下方的内容之前,将这些Alpha值应用于这些像素.设置图层的圆角半径时,实际上是在该图层上设置了遮罩.但是也可以指定任意这招,例如有一个字母A形状的蒙版.那么,只有该图层内容的一部(即该蒙版的一部分)才会呈现.
离屏渲染(Offscreen Rendering)
离开屏渲染可以由Core Animation自动触发,也可以由应用程序强制执行.离屏渲染是将图层结构树的一部分合成/渲染到新的缓冲区中(该缓冲区不在屏幕上),然后将该缓冲区渲染到屏幕上.
当计算量非常大的时候你可能想要强制离屏渲染,缓存合成纹理/图层事一种方式.如果渲染树(所有纹理以及它们如何组合在一起)很复杂,则可以强制屏幕外渲染来缓存这些图层,然后使用该缓存来合成到屏幕上.
如果你的App包含很多图层并向把他们拼在一起来显示,那么GPU必须将所有的图层在每一帧的情况下都进行复合计算.当使用离屏渲染时,GPU首先将这些图层组合到基于新texture的位图缓存中,然后使用该texture绘制到屏幕上.现在当这些图层移动到一起的时候,GPU则使用bitmap cache 并且做少量的工作.值得注意的是,只有当图层没有改变的时候这样才会生效,如果图层改变了,GPU必须重新创建位图缓存.您可以通过将shouldRasterize设置为YES来触发此行为.
这是需要权衡的事,首先它会让性能变差,创建一个离屏缓存对于GPU来说是一个额外的步骤,假如生成的这个 bitmap从来没有被重用,那么就是性能的浪费,但是,如果可以重新使用这个bitmap,GPU也可能没有启动.您必须测量GPU利用率和帧频以查看离屏渲染是否有帮助.
离屏渲染也可能会产生副作用,如果你直接或者间接在图层上应用一个遮罩.Core Animation强制离萍渲染.这会给GPU造成负担.通常,它只能直接渲染到帧缓冲区(屏幕)上. Instruments’ Core Animation 有一个功能 Color Offscreen-Rendered Yellow,它将把离屏缓存区标记为黄色,同时Color Hits Green and Misses Red也要勾选上,绿色代表离屏缓存被重用,红色代表是重新创建的.
总的来说,你应该避免离屏渲染,因为它消耗昂贵.计算图层直接展示在framebuffer(屏幕上)比创建一个离屏缓存区消耗小.直接将图层合成到帧缓冲区(在显示器上)要比先创建一个屏幕外缓冲区,然后将其渲染,然后将结果渲染回帧缓冲区要便宜得多.两个缓冲区的数据互相转换也是十分消耗性能的.
因此当你打开 Color Offscreen-Rendered Yellow 功能,看到黄色的块的时候就要注意了.但这不一定坏..如果Core Animation能够重用离屏渲染的结果,则如果Core Animation可以重用缓冲区,则可以提高性能.当用于离屏缓存区的图层未更改时,它可以重新使用.
另请注意,栅格化图层的空间有限.苹果公司暗示,光栅化图层/屏幕外缓冲区的屏幕大小大约是屏幕大小的两倍. 如果你使用图层的方式导致了离屏渲染,那么建议不要这么使用.使用遮罩或者设置圆角和设置阴影都会导致离屏渲染.
至于具有圆角(这只是一个特殊的蒙版)和clipsToBounds / masksToBounds的蒙版,您可能可以简单地创建本身具有圆角的内容.例如通过使用已应用正确蒙版的图像.一如既往,这是一个权衡. 如果要对设置了内容集的图层应用矩形蒙版,则可以使用contentsRect代替蒙版. 如果你将shouldRasterize设置为YES,请记住将rasterizationScale设置为contentsScale.
更多相关的复合计算的内容 (More about Compositing)
维基百科在alpha合成的数学上有更多的背景知识.稍后我们将进一步讨论内存中红色,绿色,蓝色和Alpha的表示方式.
OS X
如果您使用的是OS X,则可以在名为“ Quartz Debug”的单独应用中找到大多数这些调试选项,而不是在Instruments中. Quartz Debug是“图形工具”的一部分,可在开发人员门户上单独下载.
Core Animation & OpenGL ES
顾名思义,Core Animation可让您在屏幕上制作动画.我们会跳过谈论动画,更关注绘图.但是要注意的是,Core Animation允许您进行极其高效的渲染.这就是为什么使用Core Animation时可以每秒60帧的速度进行动画处理的原因.
核心动画的核心是OpenGL ES之上的抽象.简而言之,它使您可以使用OpenGL ES的功能,而不必处理其所有复杂性.当我们在上面谈论合成时,我们交替使用术语“layer”和“texture”.它们不是一回事,但非常相似.
核心动画层可以具有子层,因此最终得到的是层树. Core Animation所做的繁重工作是弄清楚需要(重新)绘制哪些图层,以及需要进行哪些OpenGL ES调用才能将这些图层合成到屏幕上.
举个例子,当你将Layer的内容设置为CG ImageRef那么Core Animation将创建一个OpenGL texture. 确保该图像中的位图被上传到相应的纹理等.或者,假如你重写 -drawInContext,Core Animation 将分配一个新的texture 并且确保您进行的Core Graphics调用将转换为该纹理的位图数据.图层的属性和CALayer子类会影响OpenGL渲染的执行方式,许多较低级别的OpenGL ES行为都很好地封装在易于理解的CALayer概念中.
Core Animation通过的Core Graphics和的OpenGL ES协调CPU来进行位图绘制.而且由于Core Animation位于渲染管道中的关键位置,因此您如何使用Core Animation会极大地影响性能.
CPU边界和GPU边界 (CPU bound vs. GPU bound)
显示一些东西在屏幕上是多种组件共同努力的结果,最主要的两个硬件是CPU和GPU.P和U在他们的名字里都象征着 处理单元,当需要在屏幕上绘制时,它们都会进行处理.两者的资源也有限. 为了达到每秒60帧的性能,你必须保证两个没有超负荷工作.尽管已经达到60fps了,也要尽可能的把计算放到GPU,要让CPU运行程序代码而不是绘图.并且GPU在渲染上比CPU更高效,从而降低了系统的整体负载和功耗. 虽然绘图性能同时依赖于CPU和GPU,你必须明白哪一个限制了你的绘图性能.假如你全都使用GPU资源.那么GPU就是你的性能的瓶颈,那么这就是GPU限制,反之CPU同理 假如你遇到GPU的限制,那么必须把一些工作转移到CPU,CPU限制反之同理 如何判断自己是否遇到了GPU BOUND, 使用 OpenGL ES Driver instrument. 点击i 按钮,然后设置,勾选Device Utilization %,现在当你运行你的App 你将会看到GPU使用率,如果这个数字接近于100%,那意味着你让GPU负荷非常重. 大部分App更容易遇到CPUBound. Time Profiler instrument 可以帮助你做到这一点.
Core Graphics / Quartz 2D (Core Graphics / Quartz 2D)
Quartz 2D通常会被称为(该框架包含它):Core Graphics. Quartz 2D有很多的能力,我们可能无法在这里介绍.我们也不会讨论PDF创建,渲染,解析还有呈现这些非常复杂的比们. 只需注意,打印和PDF创建基本上与在屏幕上绘制位图完全相同,因为它都是基于Quartz 2D的. 让我们简单介绍一下Quartz 2D的主要概念.有关详细信息,请务必查看苹果公司的Quartz 2D编程指南 .
毫无疑问Quartz 2D在2D绘制方面能力非常强悍.比如有基于路径的绘图、抗锯齿渲染、透明层、分辨率等等.当然这是很底层的并且基于C的API,可能会让人望而生畏.
不过,主要概念相对简单.UIKit和AppKit都将一些Quartz 2D封装在简单的API中,即使是普通的c-api,一旦您习惯了它,也可以轻松使用它.你最终得到了一个绘图引擎,它可以完成你在Photoshop和Illustrator中所能完成的大部分工作.苹果提到iOS上的stocks应用程序是Quartz 2D用法的一个例子,因为该图是一个简单的图形示例,它使用Quartz 2D在代码中动态呈现.
当你的应用程序绘制位图时,它将以某种方式基于Quartz 2D.也就是说,你的绘图的CPU部分将由Quartz 2D执行.虽然Quartz可以做其他事情,但我们将在这里集中精力绘制位图,即在包含RGBA数据的缓冲区(内存块)上绘制结果.
假设我们要画一个八角形.我们可以用UIKit做到这一点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
UIBezierPath *path = [UIBezierPath bezierPath];
[path moveToPoint:CGPointMake(16.72, 7.22)];
[path addLineToPoint:CGPointMake(3.29, 20.83)];
[path addLineToPoint:CGPointMake(0.4, 18.05)];
[path addLineToPoint:CGPointMake(18.8, -0.47)];
[path addLineToPoint:CGPointMake(37.21, 18.05)];
[path addLineToPoint:CGPointMake(34.31, 20.83)];
[path addLineToPoint:CGPointMake(20.88, 7.22)];
[path addLineToPoint:CGPointMake(20.88, 42.18)];
[path addLineToPoint:CGPointMake(16.72, 42.18)];
[path addLineToPoint:CGPointMake(16.72, 7.22)];
[path closePath];
path.lineWidth = 1;
[[UIColor redColor] setStroke];
[path stroke];
基本上和Core Graphics的代码相符合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CGContextBeginPath(ctx);
CGContextMoveToPoint(ctx, 16.72, 7.22);
CGContextAddLineToPoint(ctx, 3.29, 20.83);
CGContextAddLineToPoint(ctx, 0.4, 18.05);
CGContextAddLineToPoint(ctx, 18.8, -0.47);
CGContextAddLineToPoint(ctx, 37.21, 18.05);
CGContextAddLineToPoint(ctx, 34.31, 20.83);
CGContextAddLineToPoint(ctx, 20.88, 7.22);
CGContextAddLineToPoint(ctx, 20.88, 42.18);
CGContextAddLineToPoint(ctx, 16.72, 42.18);
CGContextAddLineToPoint(ctx, 16.72, 7.22);
CGContextClosePath(ctx);
CGContextSetLineWidth(ctx, 1);
CGContextSetStrokeColorWithColor(ctx, [UIColor redColor].CGColor);
CGContextStrokePath(ctx)
这边抛出第一个问题:绘画画在哪里? 这边就引入了 CGContent. 我们传入的 ctx 参数就是 context.上下文定义了我们要画的地方.如果我们要实现CALayer的drawInContext:我们将被传递一个上下文.在该上下文中绘制将绘制到层的后备存储(其缓冲区).但我们也可以创建自己的上下文,即使用CGBitmapContextCreate()创建基于位图的上下文.这个函数返回一个上下文,然后我们可以将它传递给CGContext函数,以将其绘制到该上下文中,等等.
请注意UIKit版本的代码为何不需要将上下文传递到方法中.这是因为当使用UIKit或AppKit时,上下文是隐式的.UIKit维护一个上下文堆栈,UIKit方法总是将其绘制到顶部上下文中.可以使用UIGraphicsGetCurrentContext()获取该上下文.您可以使用UIGraphicsPushContext()和UIGraphicsPopContext()将上下文推送到UIKit的堆栈中.
最值得注意的是,UIKit具有方便的方法UIGraphicsBeginImageContextWithOptions()和UIGraphicsSendImageContext()来创建类似于CGBitmapContextCreate()的位图上下文.混合使用UIKit和核心图形调用非常简单:
1
2
3
4
5
6
7
8
9
UIGraphicsBeginImageContextWithOptions(CGSizeMake(45, 45), YES, 2);
CGContextRef ctx = UIGraphicsGetCurrentContext();
CGContextBeginPath(ctx);
CGContextMoveToPoint(ctx, 16.72, 7.22);
CGContextAddLineToPoint(ctx, 3.29, 20.83);
...
CGContextStrokePath(ctx);
UIGraphicsEndImageContext();
或者其他方法类似
1
2
3
4
5
6
7
8
9
10
CGContextRef ctx = CGBitmapContextCreate(NULL, 90, 90, 8, 90 * 4, space, bitmapInfo);
CGContextScaleCTM(ctx, 0.5, 0.5);
UIGraphicsPushContext(ctx);
UIBezierPath *path = [UIBezierPath bezierPath];
[path moveToPoint:CGPointMake(16.72, 7.22)];
[path addLineToPoint:CGPointMake(3.29, 20.83)];
...
[path stroke];
UIGraphicsPopContext(ctx);
CGContextRelease(ctx);
你可以使用Core Graphics做许多非常酷的事.总的来说,苹果的文件显示了它无与伦比的输出保真度.我们不能深入到所有细节,但是:核心图形有一个图形模型(由于历史原因)非常接近adobeillustrator和adobephotoshop的工作方式.大多数工具的概念都转化为核心图形.毕竟,它起源于NeXTSTEP,它使用Display PostScript.
CGLayer
我们最初认为CGLayer可以用来加速相同元素的重复绘制.但是Dave Hayden确认,这个是流言,并不是事实.
Pixels
屏幕上的像素点事由 红绿蓝复合在一起的.因此bitmap data有时也被称为 RGB data. 你可能会好奇这些数据在内存中是怎么组织的.实际上,RGB位图数据可以在内存中用有很多,很多不同的方式来表示. 稍后我们将讨论压缩数据,这又是完全不同的.现在,让我们看看RGB位图数据,其中每个颜色分量都有一个值:红色、绿色和蓝色.通常我们会有第四个组成部分:alpha.每个像素都有四个值.
Default Pixel Layouts
在iOS和OSX上,一种非常常见的格式就是朋友们所熟知的每像素32位(bpp),每个组件8位(bpc),先进行alpha预乘.在记忆中这看起来像
1
2
3
A R G B A R G B A R G B
| pixel 0 | pixel 1 | pixel 2
0 1 2 3 4 5 6 7 8 9 10 11 ...
这种格式通常称为ARGB.每个像素使用四个字节(32 bpp).每个颜色组件为一个字节(8 bpc).每个像素都有一个alpha值,它首先出现(在RGB值之前).最后,红绿色蓝色值与α预先相乘.预倍增意味着alpha值烘焙到红色、绿色和蓝色组件中.如果我们有一个橙色的颜色,它在8 bpc的RGB值将分别是240、99和24.完全不透明的橙色像素在内存中的ARGB值为255、240、99、24,采用上述布局.如果我们有一个相同颜色的像素,但是alpha值是33%,那么像素值应该是84、80、33、8. 另一种常见格式是32 bpp、8 bpc、alphanone先跳过,看起来如下:
1
2
3
4
x R G B x R G B x R G B
| pixel 0 | pixel 1 | pixel 2
0 1 2 3 4 5 6 7 8 9 10 11 ...
这也被称为xRGB.像素没有任何alpha值(假设它们是100%不透明的),但是内存布局是相同的.您可能会想知道为什么这种格式很流行,因为,如果每个像素没有未使用的字节,我们将节省25%的空间.不过,事实证明,这种格式更容易被现代CPU和成像算法消化,因为每个像素都与32位边界对齐.现代CPU不喜欢加载(读取)未对齐的数据.这些算法必须进行大量的移位和掩蔽,特别是在将这种格式与上述具有alpha的格式混合时. 在处理RGB数据时,核心图形还支持将alpha值放在最后(以及另外跳过).它们有时分别被称为RGBA和RGBx,隐含地假设8 bpc和预乘α.
大多数时候,当处理位图数据时,我们和 Core Graphics/Quartz 2D打交道,它有一个非常具体的格式组合列表,它支持.但是,让我们首先看看剩余的RGB格式: 另一个选择是16个基点,5个基点没有阿尔法.与之前的布局相比,这种布局只占用50%的内存(每像素2个字节).如果您需要在内存或磁盘上存储(未压缩的)RGB数据,这会很方便.但由于这种格式每像素只有5位,图像(尤其是平滑渐变)可能会产生带状伪影
相反,有64个bpp,16个bpc,最后是128bpp,32bpc,float组件(不管有没有alpha).它们每像素分别使用8个字节和16个字节,并且允许更高的保真度,代价是更高的内存使用率和更高的计算开销.
为了更全面,核心图形还支持一些灰度和CMYK格式,以及alpha-only格式(用于遮罩).
Planar Data
大多数框架(包括核心图形)使用像素数据,其中组件(红、绿、蓝、阿尔法)混合在一起.在某些情况下,我们会遇到所谓的平面构件,或构件平面.这意味着每个颜色分量都在自己的记忆区域,即平面上.对于RGB数据,我们有三个独立的存储区域,一个大区域包含所有像素的红色值,一个包含所有像素的绿色值,另一个包含所有像素的蓝色值.
在某些情况下,一些视频框架将使用平面数据.
YCbCr
在处理视频数据时,YCbCr是一种相对常见的格式.它还由三个部分(Y、Cb和Cr)组成,可以表示颜色数据.但是(简而言之)它更像人类视觉感知颜色的方式.人类视觉对两个色度Cb和Cr的保真度不太敏感,但对luma Y的保真度非常敏感.当数据为YCbCr格式时,Cb和Cr的压缩比Y的压缩更困难在保证相同的精度情况下. 出于同样的原因,JPEG图像有时也会将像素数据从RGB转换为YCbCr.JPEG独立压缩每个颜色平面.在压缩基于YCbCr的平面时,Cb和Cr的压缩比Y平面更大
Image Formats
在iOS和OS X中 Images通常是JPEG 和 PNG格式的,让我们进一步了解下
JPEG
大家都知道JPEG.是相机拍照产生的东西.这就是照片在电脑上的存储方式.甚至你妈妈也听说过JPEG. 很多人认为JPEG文件只是另一种格式化像素数据的方式,这意味着我们刚刚讨论过的RGB像素布局.不过,这与事实相去甚远.
将JPEG数据转换为像素数据是一个非常复杂的过程,即使是在一个很长的周末,你也做不到.JPEG压缩是基于空间频率的算法进行了变换.这些信息然后被量化,排序,并使用哈夫曼编码的变体打包.通常,最初,数据从RGB转换到YCbCr平面.当解码JPEG时,所有这些都必须反向解码.
这就是为什么当你从一个JPEG文件创建一个UIImage并将其绘制到屏幕上时,会有一个延迟,因为CPU正忙于解压缩JPEG.假如你的每一个tableViewCell都需要解压一张JPEG图片,那么滑动肯定不会很顺畅.
那为什么要用JPEG呢?答案是JPEG可以非常非常好地压缩照片.一张来自iphone5的未压缩照片将占用将近24MB的空间.通常情况下,您的相机默认设置为3MB.JPEG压缩效果很好,因为它是有损的.它丢弃了人眼不太容易察觉的信息,这样一来,它能过大大的超过普通压缩算法例如gzip等所能压缩的极限.但这只适用于照片,因为JPEG依赖于这样一个事实,即照片中有很多人类视觉不太容易察觉的东西.如果你对一个主要显示文本的网页进行屏幕截图,JPEG的效果就不太好.压缩会降低,您很可能会看到JPEG压缩改变了图像.
PNG
PNG的发音是“ping”.与JPEG相反,它是一种无损压缩格式.当您将一个图像保存为PNG,然后打开它(并解压缩),所有像素数据都是原来的样子.由于这个限制,PNG不能像JPEG那样压缩照片,但是对于按钮、图标等应用程序的图片,它实际上非常有效.而且,解码PNG数据比解码JPEG要简单得多.
在真实世界中,事情就简单多了,其实就是一系列不同的png格式.Wikipedia可以了解更多,简单的说,对于是否带有alpha通道的图片PNG都是可以支持压缩的.这就是为什么它可以很好地用于应用插图的另一个原因.
选择格式 (Picking a Format)
当你在App中使用图片的时候,你必须从JPEG和PNG中二选一.因为他们的压缩和解压是的在读和写的性能上有了高度的优化,甚至支持并行化.并且随着OS的更新,你将免费获得苹果对于解压器的持续优化.如果您想使用其他格式,请注意,这可能会影响应用程序的性能,并且还可能带来安全漏洞,因为图像解压缩器是攻击者的最爱目标.
关于优化PNG的文章颇多.如果您愿意,可以自己在网上搜索.不过,请务必注意,Xcode的优化PNG选项与大多数其他优化引擎完全不同.
当Xcode优化PNG文件时,从技术上讲,这会将这些PNG文件转换为不再有效的PNG.但是iOS可以读取这些文件,并且实际上可以比普通PNG更快地解压缩这些文件.Xcode对它们进行了更改,使iOS使用更有效的解压缩算法,该算法不适用于常规PNG.值得注意的要点是它会更改像素布局.正如我们在“像素”下提到的,有很多方法可以表示RGB数据,如果格式不是iOS图形系统所需的格式,则需要为每个像素移动数据.不必这样做可以加快处理速度.
最后,再次强调下:如果可以的话,你应该使用可调整大小的图像.您的文件将变小,因此需要从文件系统加载然后解压缩的数据更少.
UIKit and Pixels
在UIKit中每一个View都有自己的CALayer. 这个图层有一个backing store, 这是一个pixel bitmap有点像一张图片,最后在屏幕上进行渲染的就是这个图片.
With -drawRect:
如果你的View实现了 -drawRect: 函数,他的工作原理是这样的
当您调用-setNeedsDisplay时,UIKit将在视图层上调用-setNeedsDisplay.这将在该层上设置一个标志,将其标记为脏,以进行显示.它实际上没有做任何工作,因此连续多次调用-setNeedsDisplay是完全可以接受的.
接下来,当渲染系统准备就绪时,它将在该视图的图层上调用-display.此时,该层将建立其backing store.然后,它设置由该backing store的内存区域核心图形上下文(CGContextRef).然后使用该CGContextRef进行绘制将进入该内存区域.
当你在 -drawRect:函数中使用UIKit的绘图函数 例如UIRectFill() or -[UIBezierPath fill], 你讲使用这个context. UIKit从backing store中提取出 CGContentRef到 图层上下文堆栈中. 它将使这个context成为当前的上下文. 虽然 UIGraphicsGetCurrent() 可以拿到当前的上下文. 只要UIKit一使用UIGraphicsGetCurrent()方法,那么绘图将会置入到图层的backing store. 如果你想直接使用Core Graphics的方法,你可以使用UIGraphicsGetCurrent()获得相同的上下文.并且将这个上下文传递到Core Graphics 函数中.
这样,图层的backing store将迅速的直接渲染在屏幕上直到页面的 setNeedsDisplay函数被调用.进而导致图层的backing store被更新.
Without -drawRect:
当你使用UIImageView时,工作原理略有不同.图层一样有CALayer.但是这个图层不会申请一个backing store. 取而代之的是,它使用CGImageRef作为其内容,渲染服务器会将图像的位绘制到帧缓冲区中,即绘制到显示器上.
在这种情况下,不会进行任何绘图.我们只是将位图数据以图形式传递给UIImageView,然后将其转发给Core Animation,然后由Core Animation将其转发给渲染引擎.
To -drawRect: or Not to -drawRect:
听起来有些俗气,但是:最快的绘图是您不做的绘图. 在大多数情况下,你能够避免将你自定义的视图和其他视图进行复合计算,或者将它和一个或多个layer进行复合计算.有关更多信息,请查看克里斯关于自定义控件的文章().推荐这样做,因为UIKit的视图类已经过优化.
何时需要自定义绘图代码的一个很好的例子是 苹果公司在WWDC 2012’s session 506的“finger painting”应用程序进行过论述:优化2D图形和动画性能.
使用自定义绘图的另一个地方是iOS股票应用.股票图是在带有Core Graphics的设备上绘制的.请注意,因为您要进行自定义绘制,所以不一定需要使用-drawRect:方法.有时,使用UIGraphicsBeginImageContextWithOptions()或CGBitmapContextCreate()创建位图,从中获取结果图像并将其设置为CALayer的内容可能更有意义.测试和测量.我们将在下面给出一个示例.
Solid Colors
看下下面的例子
1
2
3
4
5
6
// Don't do this
- (void)drawRect:(CGRect)rect
{
[[UIColor redColor] setFill];
UIRectFill([self bounds]);
}
我们现在知道为什么这很糟糕,我们正在促使Core Animation为我们创建一个后备存储,并要求Core Graphics用纯色填充该后备存储.然后必须将其上传到GPU.
我们可以完全不执行-drawRect:来保存所有这些工作,而只需设置视图图层的backgroundColor即可.如果视图的图层为CAGradientLayer,则对渐变使用相同的技术.
Resizable Images
同样的,你可以可调整图片大小的图片来降低图像系统的压力. 假如你想要一个 300 * 50点的按钮, 那么600 *100 = 60K的像素点或60k x 4 = 240kB的内存必须上传到GPU,然后占用VRAM. 如果我们要使用所谓的可调整大小的图像,我们可能会避开例如一个54 x 12点的图像,该图像将略低于2.6k像素或10kB的内存.事情更快.
Core Animation可以使用CALayer上的contentsCenter属性来调整图像的大小,但是在大多数情况下,你都可以使用-[UIImage resizableImageWithCapInsets:resizingMode:]来改变大小. 值得注意的是,在第一次渲染这个按钮的时候,相比于系统文件中读取60k大小的png文件然后在对60k像素的png进行解码,更小的png图片在解码的时候更为快速.这样,您的应用程序在所有相关步骤中的工作量都将减少,并且视图加载速度会更快.
Concurrent Drawing (并发绘图)
上一个objc.io问题是关于并发性的.如您所知,UIKit的线程模型非常简单:您只能在主队列(即主线程)中使用UIKit类(视图等).那么关于并发绘图是怎么回事?
假如你必须使用 -drawRect:函数, 并且要绘制一些很重要的东西.那么这将很花费时间. 因为你想要让动画更快的流畅,那么你将会尝试在另一个队列去处理数据而不是主队列. 并发是十分复杂的. 但是只要注意一些相关的事项,并发绘制也是是很可以容易实现的.
我们不能在主队列上绘制内容到CALayer的backing store区域. 这将会导致一些很糟糕的事情发生.但是我们可以绘制图像到一个完全不相关的bitmap上下文.
我们上面提及过Core Graphics的使用, Core Graphics 绘图函数将会带入一个context入参来指定一个绘图的context. 而UIKit则具有其绘图所涉及的当前上下文的概念.当前上下文是每个线程. 为了使用并发绘图功能,需要这么做. 我我们将在另一个队列创建一个image.创建后 image后 我们将切换到主队列去,将image设置到UIImageView上. 这个技巧在WWDC 2012 session 211上谈及过.
添加一种新的绘图方法:
1
2
3
4
5
6
7
8
9
10
- (UIImage *)renderInImageOfSize:(CGSize)size;
{
UIGraphicsBeginImageContextWithOptions(size, NO, 0);
// do drawing here
UIImage *result = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
return result;
}
这个方法 通过UIGraphicsBeginImageContextWithOptions() 函数创建了一个新的指定大小的bitmap 上下文. 该方法也使这个新的上下文成为当前UIKit的上下文. 现在你可以用 -drawRect: 绘制出你想要的. 然后你通过UIGraphicsGetImageFromCurrentImageContext(),将 bitmap数据转成UIImage,并最终删除上下文.
值得注意的是 在这个函数中调用的绘图编码是线程安全啊. 假如你需要访问属性等等,他们必须是线程安全的. 因为你将会在另一个队列调用这个方法. 假如这个方法是在你的view class上,就会有一点复杂. 因为更简单的选择是你单独创建一个包含所有需要的属性的渲染类,只有在被触发的时候才会渲染图片. 如果是这样,您也许可以使用普通的UIImageView或UITableViewCell.
注意下 所有的UIKit的绘图APIs在另一个队列使用是安全的.只要确保他们在一个动作中并且用UIGraphicsBeginImageContextWithOptions() 开头 和 UIGraphicsEndIamgeContext() 结尾.
触发渲染代码有点类似下面的代码
1
2
3
4
5
6
7
8
9
10
UIImageView *view; // assume we have this
NSOperationQueue *renderQueue; // assume we have this
CGSize size = view.bounds.size;
[renderQueue addOperationWithBlock:^(){
UIImage *image = [renderer renderInImageOfSize:size];
[[NSOperationQueue mainQueue] addOperationWithBlock:^(){
view.image = image;
}];
}];
这里一定要在主队列 执行 view.image = image 代码.这非常重要,你不要在其他任何队列执行它. 当然并发将会带来一系列复杂的问题. 您现在可能必须实现取消背景渲染.而且,您很可能必须在渲染队列上设置合理的最大并发操作数.同时你可能必须在渲染队列上设置一个最大的操作并发数.
为了支持所有这些,最有可能在NSOperation子类中实现-renderInImageOfSize:. 最后,需要指出在 UITableViewCell中进行异步操作是非常困难的,以为cell当异步渲染完成时候很可能cell已经被重用了.或者你在上面设置的其他内容而当前cell已经被用作其他用途.
CALayer Odds and Ends
到目前为止你应该明白 CALayer是类似相近于 texture对于GPU来说,该图层具有一个后备存储,存储在上面的位图片绘制到显示器上.
通常,当你使用CALayer. 你将会设置contents属性为image. 这么做是为了告诉Core Animation 在texture中使用图片的bitmap data. 如果图像被压缩(JPEG或PNG),Core Animation将导致图像被解码,然后将像素数据上传到GPU.
尽管还有很多种其他种类的layers.但是假如你使用普通的 CALayer.不设置contents.并且设置了背景色.Core Animation 不会上传任何数据到GPU,但是无需任何像素数据就可以在GPU上完成所有工作.渐变层类似.GPU不需要CPU的任何帮忙就可以创建一个渐变层,并且也不需要任何数据传递给GPU.
Layers with Custom Drawing
假如CALayer子类实现了 -drawInContext:或者它的代理. -drawLayer:inContext: Core Animation将为该层分配一个Backing store,这些方法会将这些bitmap绘制出来. 这些函数中的代码是在CPU中计算,然后将计算结果上传给GPU.
Shape and Text Layers
在图形和文本上事情就有些不一样了,首先 Core Animation 申请了backing store给这些图层来保存为contents 生成的bitmap数据. Core Animtion将绘制这些图层或者文本到backing store. 从概念上讲,这与您实现-drawInContext:的情况非常相似,并且会在该方法内绘制形状或文本.而且性能也将非常相似.
当您以需要更新后备存储器的方式更改形状或文本图层时,Core Animation将重新渲染后备存储器.例如.在为形状图层的大小设置动画时,Core Animation必须为动画中的每个帧重新绘制形状.
Asynchronous Drawing
CALayer有一个属性 drawsAsynchronously. 这似乎是解决所有问题的灵丹妙药.但是请注意,它可能会提高性能,但也可能会使速度变慢.当您将drawsAsynchronously设置为YES时,会发生-drawRect:/ -drawInContext:方法仍将在主线程上被调用的情况.但是,对Core Graphics的所有调用(因此也包括UIKit的Graphics API,后者又称为Core Graphics)均不执行任何绘制.取而代之的是,在后台线程中延迟并异步处理绘图命令.
一种查看方式是,先记录绘图命令,然后再在后台线程上重放它们.为了使它起作用,必须完成更多的工作,并且需要分配更多的内存.但是有些工作被移出了主队列.测试和测量.
对于昂贵的绘图方法,它最有可能提高性能,而对于廉价的绘图方法,它的可能性较小.